DALL-E 및 사용 후기
DALL-E의 작동 원리와 실제 사용 후기 정리
OpenAI에서 개발한 이미지 생성 AI예요. 텍스트 설명으로 관련된 이미지를 만들어내죠.
DALL-E의 이름은 살바도르 달리와 월-E의 결합에서 생각해냈다고 합니다.
 DALL-E 로고
DALL-E 로고
DALL-E 1
DALL-E 1은 GAN과 같이 이미지를 생성하는 모델이지만, 그 구조는 GAN보다는 GPT-3에 가깝습니다.
GPT-3는 Transformer의 Decoder 부분만을 사용하는 Generative 모델로, 입력받은 단어의 token sequence를 가지고 다음 단어 token을 차례차례 예측하는 방식입니다.
DALL-E 1에서도 기본 작동 방식은 같지만 출력에서 예측하는 결과가 token이 아니라 이미지의 pixel이라는 것이 다릅니다.
입력받은 이미지를 256x256 크기로 조정한 후 VQ-VAE로 처리하여 32x32, 즉 1024개의 token으로 변환합니다. 원래 데이터를 그대로 학습하려면 약 20만개의 token이 입력되어야 하지만 이를 단 1024개로 줄인 것입니다.
DALL-E 2
DALL-E 1과 DALL-E 2는 기본적인 동작은 크게 다르지 않습니다. 큰 그림으로 보면 아래 3단계로 동작해요.
- 텍스트 프롬프트를 텍스트 인코더에 입력
- prior 모델이 텍스트 인코딩을 이미지 인코딩으로 매핑하여 프롬프트의 의미 정보를 포착
- 이미지 디코더가 프롬프트의 의미 정보를 시각적으로 표현한 이미지를 생성
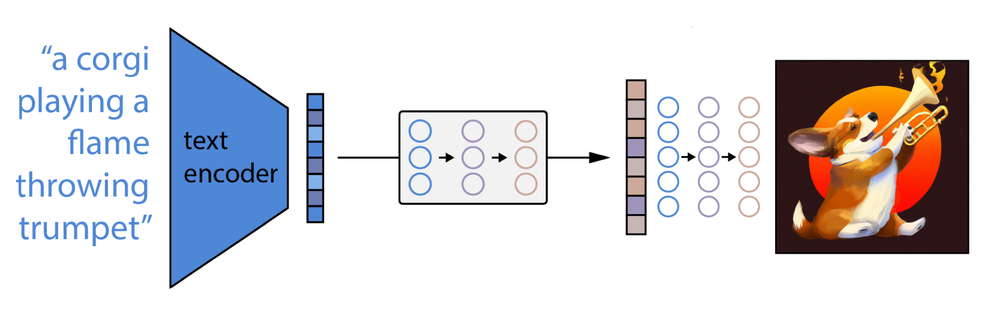 DALL-E 2 아키텍처 구조
DALL-E 2 아키텍처 구조
CLIP
DALL-E 2가 텍스트 개념이 시각적 공간에서 어떻게 표현되는지 아는 것은 CLIP이라는 OpenAI 모델 덕분입니다.
CLIP은 텍스트와 이미지 데이터를 모두 이해하는 인공지능 모델입니다. 대규모 데이터 셋을 사용하여 동시에 이미지와 텍스트 데이터를 학습시킵니다. 이 과정에서 모델은 이미지와 텍스트 간의 의미론적 관계를 파악하게 됩니다.
학습 방법은 Contrastive Learning을 사용합니다. 비슷한 특성을 가진 데이터 샘플 간의 거리를 줄이고, 다른 특성을 가진 샘플 간의 거리를 멀게 만드는 방식입니다.
 DALL-E 2 생성 예시: 서울 경복궁 앞을 걸어가는 곰인형
DALL-E 2 생성 예시: 서울 경복궁 앞을 걸어가는 곰인형
사용 후기
- OpenAI에서 API를 제공해 줘서 사용성은 최고
- txt2img, img2img, img2img inpaint 3개의 기능을 API로 제공
- 한글을 못 알아들어서 프롬프트는 영어로 적어야 함
- 지원하는 사이즈: 256x256, 512x512, 1024x1024
- 리사이즈 시 투명 영역은 DALL-E가 연결해서 그림
Inpaint 기능 예시
 원본 이미지
원본 이미지
 눈 감은 표정으로 수정
눈 감은 표정으로 수정
 원본 이미지
원본 이미지
 사람 삭제 및 resize
사람 삭제 및 resize
결론
DALL-E를 써봤는데, 아직 만족할 만한 성능은 아니었어요.
DALL-E 2로 DALL-E 홈페이지에서 사용한다면 모르겠지만 API로 제공하는 기능은 몇 가지 없기 때문에 프로덕트에 적용하는 것은 시기상조로 보입니다. (2023년 4월 기준)
프로덕션 적용하려면 이런 추가 작업이 필요해요.
- 한글-영어 번역 시스템 구축
- 이미지 리사이징 파이프라인 구현